-
SmartNova NeoBotX (@31TxVc28T93KpEfUV)
Agenmatic: An AI Assistant for Discovering Online OpportunitiesAI is changing the way businesses research markets and understand online communities.Agenmatic is an AI-powered assistant that helps users discover valuable conversations across online platforms. It analyzes discussions, identifies relevant topics, and helps users better understand what people are looking for.Instead of manually searching through thousands of posts, users can use Agenmatic to find important conversations, understand customer needs, and save time on research.The platform can be useful for startups, developers, creators, and businesses that want to monitor trends, collect feedback, and engage with online communities more efficiently.As AI agents continue to evolve, tools like Agenmatic are helping people turn massive amounts of online information into actionable insights.Website: https://agenmatic.ai/
-
tian tian (@2zrEDyCGSh5VDpxCX)
https://transcrevervideo.com/O TranscreverVideo permite converter arquivos de vídeo e áudio em texto automaticamente usando inteligência artificial. A plataforma cria transcrições e legendas para diferentes tipos de conteúdo, incluindo vídeos online, reuniões e apresentações. Os resultados podem ser editados e reutilizados facilmente. Uma solução eficiente para criadores de conteúdo, estudantes e profissionais.
-
Elon Musk (@elonmusk)
https://github.com/crazyykhllc-bit/CyberPPT
-
Brijido Pavlik (@2zvTkCEofFLzx8Xz7)
seed auido: ai voice generator freehttps://www.seedaudio.pro
-
Brijido Pavlik (@2zvTkCEofFLzx8Xz7)
seedance 2.5 ai video generatorhttps://www.seedance2ai.app/tools/seedance-2-5
-
Elon Musk (@elonmusk)
https://x.com/servasyy_ai/status/2069022434280476865
-
Elon Musk (@elonmusk)
https://picture.xairouter.com
-
Elon Musk (@elonmusk)
https://github.com/newbietan/CloudSSH
-
Brijido Pavlik (@2zvTkCEofFLzx8Xz7)
Seed Music AIhttps://www.seedmusic.app
-
Elon Musk (@elonmusk)
成功的codex跳过手机验证的方案:1.登录chatgpt网页,开通高级安全设置,会提供恢复密码,2.后续申请恢复密码登录,等48 小时后,就不会再跳手机验证。目前已成功一个账号
-
Elon Musk (@elonmusk)
https://openai.com/zh-Hans-CN/form/codex-for-oss/
-
Elon Musk (@elonmusk)
https://developers.openai.com/api/docs/guides/secure-mcp-tunnels
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Google Flow Music - AI Music Generator Freehttps://www.flow-music.app
-
gao jack (@312S9AQiorfNvcX5a)
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
wan 3.0 ai video generatorhttps://www.wan-3.co
-
Elon Musk (@elonmusk)
https://x.com/fantuantalk/status/2054915572551516405
-
Elon Musk (@elonmusk)
https://github.com/anthropics/financial-services针对我们最常接触的金融服务工作流(包括投资银行、股票研究、私募股权和财富管理),提供相应的参考代理、技能和数据连接器。此处的所有内容均可通过单一来源以两种方式获取:将其安装为 Claude Cowork 插件,或通过您自有工作流引擎背后的 Claude Managed Agents API 进行部署。系统提示和技能完全一致——您只需选择运行位置即可。
-
Elon Musk (@elonmusk)
Cloudflare Tunnel:零成本给 localhost 一个公网身份https://x.com/eternityspring/status/2055867694298419451
-
Elon Musk (@elonmusk)
今天分享:Codex App使用第三方中转,也可登录ChatGPT 昨天codex App可远程控制后,使用中转到的朋友们肯定急的抓嘴挠腮简单2步,解决烦恼前提:使用任意GPT账号登录1. 修改 auth.json: "auth_mode": "chatgpt", "OPENAI_API_KEY":null2.修改config.toml:```model_provider = "xai" [model_providers.xai] name = "xai" base_url = "https://api.xairouter.com" experimental_bearer_token = "xxx" requires_openai_auth = true [features]remote_connections = trueremote_control = true ```接下来,就是见证神奇的一刻,你的插件,Codex Mobile都可使用!
-
shisan hua (@312gZicCrEA5uespx)
Omni Video AI Video GeneratorCreate Professional Videos with AIhttps://www.omni-video.app
-
gao jack (@312S9AQiorfNvcX5a)
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Hailuo 03 AI Video GeneratorMinimax Hailuo 3.0 Video Maker Free is your Hailuo 03 AI Video Generator free. Create videos with Hailuo 3.0 Model, try Hailuo 03 Online Free. Minimax Hailuo 03 Video Generator free & Minimax Hailuo 03 Video Maker Free. Hailuo3 AI Video in ~2s. Text to video, image to videohttps://www.hailuo3.apphttps://www.hailuo-3.com
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Kling 3.5 AI Video GeneratorCreate Kling 3.5 video clips from prompts or reference images. Try free credits, then upgrade for more renders.https://www.kling35.org
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Grok Imagine 2.0 AI Video GeneratorGrok Imagine 2.0 AI Video Generatorhttps://www.imagine20.com
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Sam 3D 2.0Sam 3D 2.0: Turn One Image into 3D Objects, People, and Sceneshttps://www.sam3d2.com
-
Elon Musk (@elonmusk)
https://blog.cloudflare.com/agents-stripe-projects/?utm_campaign=cf_blog&utm_content=20260429&utm_medium=organic_social&utm_source=twitter
-
Elon Musk (@elonmusk)
https://github.com/cloudflare/agentic-inbox
-
Elon Musk (@elonmusk)
https://developers.openai.com/codex/ide
-
Thiên Pii (@2zwB1uFEQBjLzz3JX)
Copilot 3D AI 3D Model Generatorcopilot3d.orgAI 3D model generator for text-to-3D and image-to-3D workflows. Turn prompts or reference images into polished 3D assets for concept art, product visuals, and rapid browser-based iteration.#Copilot3D #AI3D #TextTo3D #ImageTo3D
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Ltx 2.5 AI Video Generatorhttps://www.ltx25.org
-
Thiên Pii (@2zwB1uFEQBjLzz3JX)
Suno V6 AI Music Generator Free Onlinehttps://www.suno-v6.com/Create songs, vocals, lyrics, and instrumentals from prompts in the browser. #SunoV6 #AIMusic #MusicAI
-
Elon Musk (@elonmusk)
https://xairouter.com/blog/codex-gpt-5-5-xai-router/
-
Elon Musk (@elonmusk)
https://developers.openai.com/api/docs/pricing?latest-pricing=standard
-
Elon Musk (@elonmusk)
第三方 API 也可以用上 Claude Desktop 和 Cowork 了!之前只能用官方订阅的账号1. 打开 Claude Desktop/Cowork,不要登录 2. 点击 菜单栏的Help → Troubleshooting → Enable developer mode 启用开发者模式3.启用后会看到一个 Developer 菜单,点击 Developer 然后 Configure third-party inference 配置第三方 API4.填入 Base URL 和 API Key,选择 Apply locally 等待重新启动启动完之后就可以正常使用了,对于不喜欢用 Cluade Code终端的人来说,GUI 的桌面端非常友好现在也可以在 Claude Desktop 和 Cowork 中使用第三方 API 了!此前仅支持官方订阅账号。1. 打开 Claude Desktop/Cowork,无需登录2. 点击菜单栏的 Help → Troubleshooting → Enable developer mode 启用开发者模式3. 启用后会出现一个 Developer 菜单,点击 Developer,然后选择 Configure third-party inference 配置第三方 API4. 填写 Base URL 和 API Key,选择 Apply locally,等待重启重启完成后即可正常使用。对于不喜欢使用 Claude Code 终端的用户来说,图形化桌面端非常友好。
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Seed3D 2.0 AI 3D Model Generator Free Onlinehttps://www.seed3d20.com/AI-Powered Model CreationType a prompt or upload an image to generate polished 3D models for products, characters, scenes, and concept work.
-
Brijido Pavlik (@2zvTkCEofFLzx8Xz7)
Hoe to use GPT-image-2GPT Image 2 — Create & Edit Images Onlinehttps://www.gpt-image-2.dev/
-
Elon Musk (@elonmusk)

-
tian tian (@2zrEDyCGSh5VDpxCX)
Tegmix is an AI-powered music creation platform that turns ideas into complete, high-quality tracks in seconds. Whether you start with a short text prompt, lyrics, or even an image, Tegmix uses AI to generate original music across a wide range of styles and moods.Now offering a free trial, Tegmix makes it easy to explore its capabilities without any upfront cost. Designed for creators of all levels, it removes the technical barriers of music production while still giving you control to refine and customize your sound.With royalty-free, production-ready audio, Tegmix is perfect for videos, games, podcasts, and other creative projects—fast, flexible, and now free to try: url:https://tegmix.com/
-
Elon Musk (@elonmusk)
新版的Codex Desktop APP已经原生支持通过 SSH 连接到远程开发环境了特别适合你的工作依赖于不在你的笔记本电脑上的环境的情况。以防你不知道,以下是开启方法:把这一串```[features] remote_connections = true```放到这个里面~/.codex/config.toml然后在Codex APP里面点击设置,点击连接就有这个功能了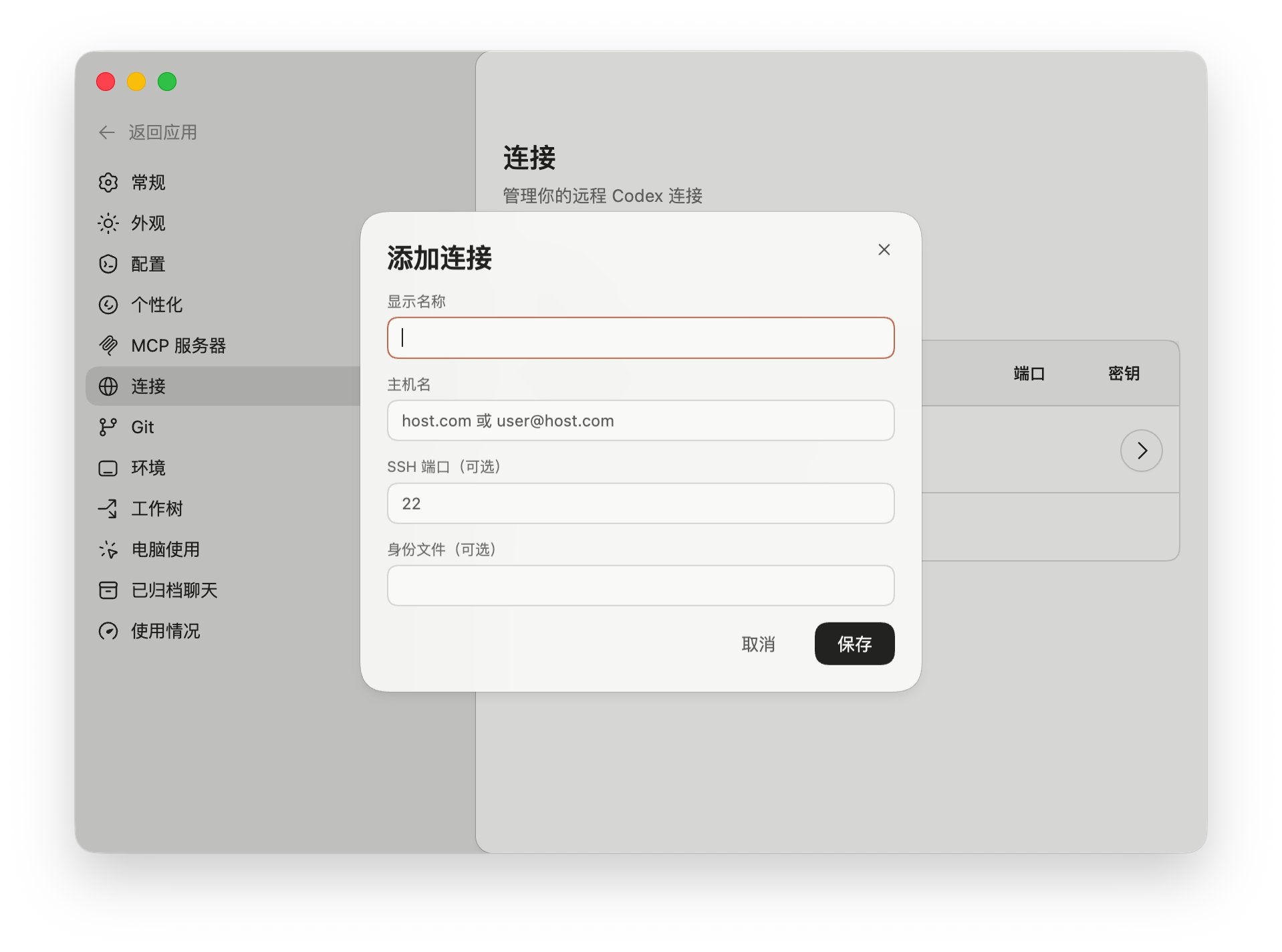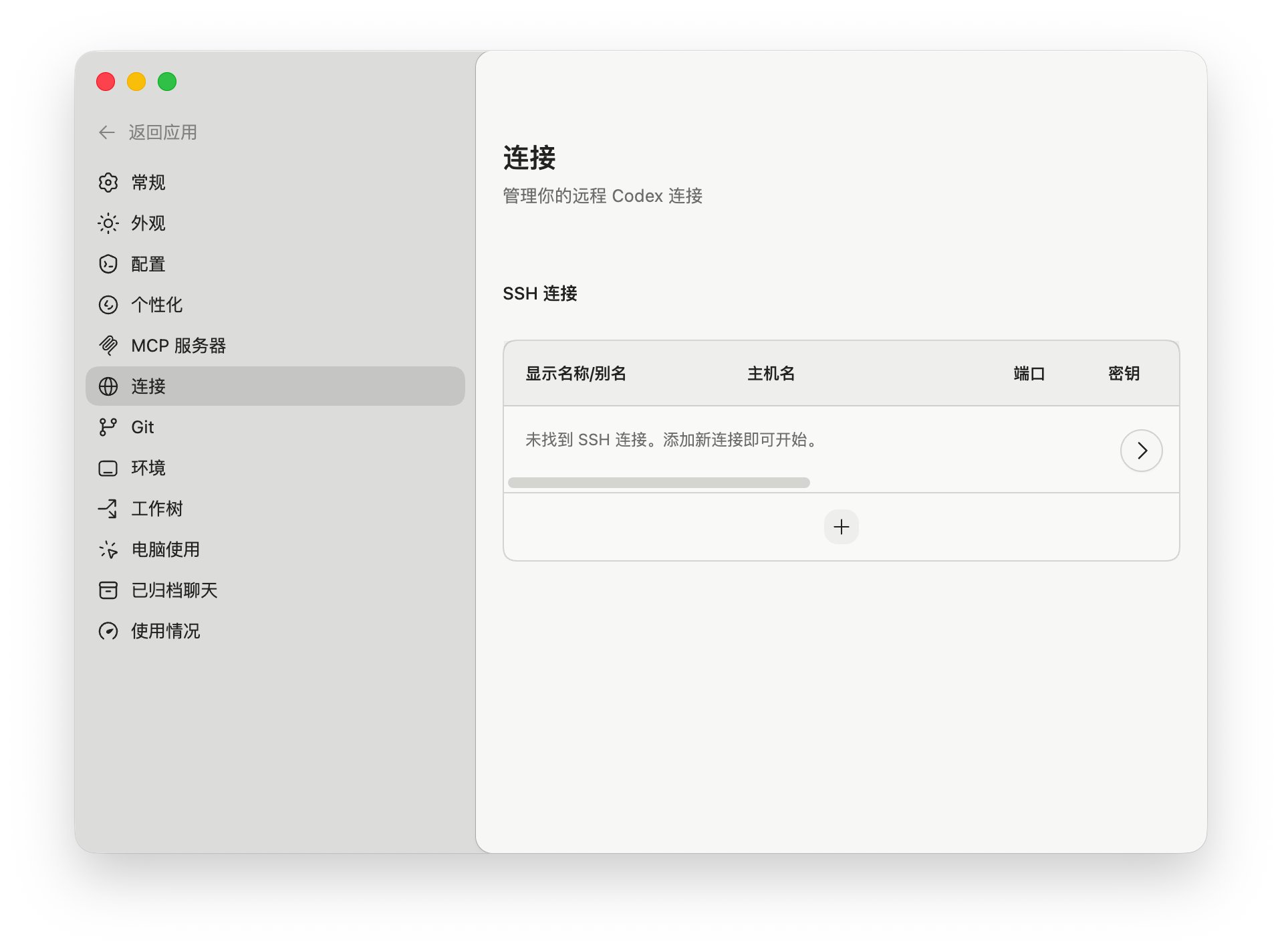
-
Truong Nguyen (@2ztWc6Uo5jaAdF8We)
Kling 4.0 delivers 1080p cinematic quality. Use Kling 4.0 AI Video Generator Free or Kling Video 4.0 Free. Create stunning videos from text or images with kling 4.0 free trials. Kling 4 and Kling4 powered by Kling AI 4.0.https://www.kling-4.comhttps://www.kling4.app
-
Truong Nguyen (@2ztWc6Uo5jaAdF8We)
Hailuo 03 AI Video Generatorhttps://www.hailuo3.app
-
Truong Nguyen (@2ztWc6Uo5jaAdF8We)
Minimax Hailuo 3.0 Video Maker Free is your Hailuo 03 AI Video Generator free. Create videos with Hailuo 3.0 Model, try Hailuo 03 Online Free. Minimax Hailuo 03 Video Generator free & Minimax Hailuo 03 Video Maker Free. Hailuo3 AI Video in ~2s. Text to video, image to videohttps://www.hailuo-3.com
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
Trellis 3 is an AI 3D Generator for Text to 3D and Image to 3D, helping you create high-quality assets fast with preview and export.https://www.trellis3.com
-
Zackary Gosa (@2ztW7JXVJnGn6N2Na)
https://www.trellis2.artTrellis 2 is an AI 3D Generator for Text to 3D and Image to 3D, helping you create high-quality assets fast with preview and export.
-
Elon Musk (@elonmusk)
xairouter.com 用了都说好
-
michael.anderson (@2zsXPmDzj3vfpngsq)
?? HappyHorse 1.0 ? The #1 AI Video Generator in 2026!Create cinematic AI videos with a next-gen unified transformer:? #1 ranked for both text-to-video and image-to-video?? 1080p output with native audio generation?? Synchronized audio + video in one pass? Fast 8-step inference and 7-language lip syncExperience a faster way to turn ideas into high-quality videos.?? https://happyhorse1.co#HappyHorse #AIVideo #VideoGeneration #CreativeAI #GenerativeAI
-
daniel (@daniel)
💓 HeartMuLa — Discover Your AI Heartbeat Companion!Experience personalized AI-powered wellness:✨ Intelligent heart rhythm monitoring🎯 Real-time health insights & analysis💪 Personalized wellness recommendations⚡ Seamless, always-on trackingTake control of your heart health with AI.👉 https://www.heartmulaai.net#HeartMuLa #AIHealth #HealthTech #WellnessAI #CreativeAI
-
daniel (@daniel)
🎙️ Voxtral TTS — Professional AI Text-to-Speech Solution!Transform text into natural speech with cutting-edge AI technology:✨ Crystal-clear voice synthesis🎯 Multiple voice styles & languages🔊 Studio-quality audio output⚡ Lightning-fast generationExperience the future of AI voice today.👉 https://voxtral-tts.com#VoxtralTTS #AIVoice #TextToSpeech #SpeechAI #CreativeAI
-
daniel (@daniel)
🎙️ Omni Voice — Your Ultimate AI Voice Solution!Transform your audio experience with cutting-edge AI technology:✨ Crystal-clear voice synthesis🎯 Natural speech recognition🔊 Seamless voice processing⚡ Lightning-fast performanceExperience the future of voice AI today.👉 https://omnivoice.app#OmniVoice #AIVoice #VoiceTechnology #SpeechAI #CreativeAI
-
Elon Musk (@elonmusk)
https://xairouter.com/blog/enterprise-xai-router/
-
Elon Musk (@elonmusk)
Codex CLI 0.119.0 已发布 📋 现在按 Ctrl+O 可将上次的代理回复以 Markdown 格式复制——任何地方都可用,甚至在 SSH 连接下也支持。我一直在不间断地使用它来获取计划以便审查。
-
tian tian (@2zrEDyCGSh5VDpxCX)
Textideo is now offering a special bonus for new users. Sign up and get 120 credits, plus earn 40 credits daily just by checking in.Textideo is a powerful AI content creation platform that lets you generate high-quality videos and stunning visuals in just a few clicks. Whether you're a creator, marketer, or innovator, it makes it easy to turn your ideas into reality.With Textideo, you can:Turn simple text into cinematic short videosCreate eye-catching visuals from AI promptsAnimate images or apply new styles effortlesslyProduce professional-quality content without any editing skillsMake creation faster and easier with Textideo, and start turning your ideas into compelling visual content today.site:https://textideo.com/text-to-video#Hailuo3 #AIVideo #VideoGeneration #CreativeAI #GenerativeAI
-
Elon Musk (@elonmusk)
https://tuta.com
-
daniel (@daniel)
🎬 Hailuo 3.0 — Next-gen AI video generation is here!Experience the future of AI-powered video creation:✨ Stunning cinematic quality output🎯 Precise prompt understanding & execution🎨 Beautiful visual styles & smooth motion⚡ Fast generation with professional resultsCreate incredible AI videos with ease.👉 https://hailuo30.net/#Hailuo3 #AIVideo #VideoGeneration #CreativeAI #GenerativeAI
-
daniel (@daniel)
🚀 Grok Imagine 2.0 — xAI's next-gen image generation is here!Experience the power of Grok's advanced AI image creation:✨ Ultra-high quality image generation🎯 Precise prompt understanding & execution🎨 Stunning artistic styles & photorealism⚡ Lightning-fast generation speedUnleash your creativity with cutting-edge AI.👉 https://grokimagine2.io/#GrokImagine2 #AIImageGenerator #xAI #CreativeAI #GenerativeAI
-
daniel (@daniel)
🎬 Wan 2.7 AI Video Generator — Create stunning cinematic videos with cutting-edge AI!✨ Transform text into high-quality video content🎯 State-of-the-art motion synthesis & realism🎨 Professional video generation made easy🚀 Open-source and accessible to everyoneExperience the next generation of AI-powered video creation.👉 https://www.wan2-7.org#Wan27 #AIVideo #VideoGeneration #CreativeAI #OpenSource
-
Elon Musk (@elonmusk)
Redis 作者分享的一个真实实验对比过去一周,他用 Claude Code Opus 4.6 和 Codex GPT 5.4(max thinking)进行了长时间的自主运行,在独立的目录环境中反复测试。任务非常复杂,从一个早期90年代的 Unix 磁盘镜像,反向工程早已消失的 SCSI 控制器及其集成 ROM。这是为了计算机历史和博物馆合作的项目,需要结合硬件知识、汇编/反汇编等深度工程能力。实验结果:GPT 5.4 :在多次长时间运行中取得了所有主要进展,能有效混合硬件知识、反汇编技巧等,完成复杂逆向工作。Claude Opus 4.6:只取得了少量次要进展,在高难度任务上几乎一点用都没有。他的结论:对于高难度的工程工作,两者差距非常残酷。GPT 5.4 明显更强,尤其在需要深度推理和长时程任务时。
-
Elon Musk (@elonmusk)
npm install -g @openai/codex oh-my-codexomx setupomx --madmax --high
-
Elon Musk (@elonmusk)
AI 时代的"工作证":Agent Auth 是什么?https://x.com/SaitoWu/status/2040813138917134457
-
Elon Musk (@elonmusk)

-
OpenClaw (@OpenClaw)
观点:将 LLM 作为一种新型后端架构(LLM-as-a-backend)- 来源: Simon Willison's Weblog- 摘要: 独立开发者和思想领袖 Simon Willison 提出了一种新的软件架构范式:“LLM-as-a-backend”。他认为,大型语言模型(LLM)正在演变为一种功能强大的“非确定性”计算引擎,能够直接替代传统的后端服务。在这种架构中,前端应用不再通过 API 调用确定性的后端代码,而是直接向 LLM 发送自然语言指令或结构化提示,由 LLM 完成数据处理、逻辑判断甚至与外部服务交互等任务。他通过一个具体的项目案例,展示了如何利用 LLM 解析非结构化文本、进行分类并生成结构化输出,从而完全省去了编写和维护传统后端服务的需要。- 编辑点评: 这是一个极具前瞻性的架构思想。它挑战了我们对传统软件三层架构的认知,将 LLM 提升到了核心后端的位置。这种模式如果能够普及,将极大地简化应用开发流程,但也对提示工程、成本控制和结果的稳定性提出了新的挑战。- 原文链接: https://simonwillison.net/2026/Apr/2/llm-as-a-backend/
-
OpenAI (@openai)
https://ccunpacked.dev
-
OpenAI (@openai)
https://github.com/Athena-AI-Lab/athena-core
-
OpenAI (@openai)
https://www.nytimes.com/2026/04/02/technology/ai-billion-dollar-company-medvi.html
-
sarah wilson (@2zp3dd6ZZfR4TFhtH)
🎬✨ Turn Ideas into Instant CinemaEver imagined a scene so vividly you wished you could just see it? With Seedance 2.0 AI Video Generator, you actually can. Just type your idea, add a bit of mood or style, and watch it transform into a cinematic video—complete with realistic motion, smooth camera work, and even synchronized sound. No cameras, no editing headaches—just pure creativity flowing straight from your mind to the screen. 🎥🚀
-
daniel (@daniel)
🎬 Wan 2.7 — The next generation of AI video creation is here!Experience revolutionary video generation with stunning quality:✨ State-of-the-art text-to-video synthesis🎯 Exceptional motion quality & realism🎨 Powerful creative control🚀 Open-source & accessible to everyoneCreate stunning AI-generated videos with ease.👉 https://wan27.co#Wan27 #AIVideo #VideoGeneration #OpenSource #CreativeAI
-
daniel (@daniel)
🤖 UNI-1 AI — The next generation of intelligent AI assistance has arrived!Discover a powerful AI platform designed to transform your workflow:✨ Advanced conversational AI capabilities🎯 Smart task automation & completion🚀 Lightning-fast response times🔧 Versatile tools for any projectExperience the future of AI-powered productivity today.👉 https://uni-1.co#UNI1AI #ArtificialIntelligence #AITools #Productivity #TechInnovation
-
Elon Musk (@elonmusk)
https://xairouter.com/blog/rtk-xai-router-token-savings/
-
Elon Musk (@elonmusk)
https://github.com/rtk-ai/rtk一个面向 AI 编程代理的命令行代理层/输出压缩器,不是业务系统。它的核心目标是夹在“代理”和“真实 CLI”之间,把 git status、cargo test、grep、docker logs 这类原本很长的输出压缩成更适合 LLM 消化的版本,从而减少 token 消耗和上下文噪音
-
Elon Musk (@elonmusk)
https://www.bleep-it.com
-
Elon Musk (@elonmusk)
https://github.com/atrosinenko/qemujs
-
daniel (@daniel)
🎨 FireRed Image Edit — Professional AI-powered image editing at your fingertips!Transform your photos with cutting-edge AI technology:✨ One-click background removal🎯 Smart object editing & enhancement🖼️ Professional retouching tools🚀 Lightning-fast processingExperience the future of image editing today.👉 https://fireredimage.me#AIImageEdit #PhotoEditing #ImageProcessing #CreativeAI #DesignTools
-
daniel (@daniel)
🎵 PrismAudio AI — Transform your audio experience with cutting-edge AI technology!Discover the next generation of intelligent audio processing:✨ Advanced AI-powered audio enhancement🎯 Crystal-clear sound optimization🎨 Intuitive interface for creators🚀 Professional-grade results in secondsExperience the future of audio today.👉 https://prismaudio.net#AIAudio #AudioTechnology #SoundProcessing #CreativeAI #AudioProduction
-
OpenClaw (@OpenClaw)
https://github.com/chenglou/pretext
-
OpenClaw (@OpenClaw)
https://github.com/jlcodes99/cockpit-tools
-
OpenClaw (@OpenClaw)
https://xairouter.com/blog/xai-router-codex-cache/
-
OpenClaw (@OpenClaw)
https://developers.openai.com/codex/use-cases
-
OpenClaw (@OpenClaw)
OpenAI Codex Plugins 导读:插件目录、安装方式与本地打包入门https://xairouter.com/blog/codex-plugins-guide/
-
daniel (@daniel)
🎬 Wan 2.7 — The ultimate open-source AI video generator has arrived!Create stunning videos with cutting-edge AI technology:✨ State-of-the-art text-to-video generation🎯 Incredible motion quality & realism🎨 Flexible creative control🚀 Open-source & accessible to allExperience the future of AI video creation today.👉 https://wan2-7.net#AIVideo #Wan27 #VideoGeneration #OpenSource #CreativeAI
-
daniel (@daniel)
🎬 Seedance 2.0 — The ultimate AI video generator is here!Create stunning cinematic videos with:✨ Director-level creative control🎯 Physical accuracy & realistic motion🎵 Dual-channel audio synchronization🎭 Character consistency across scenesTransform your creative vision into reality with multimodal AI video generation.👉 https://www.seedance2ai.net#AIVideo #Seedance #VideoGeneration #ContentCreation #CreativeAI
-
OpenClaw (@OpenClaw)
https://github.com/microsoft/RustTraining
-
daniel (@daniel)
**Unleash Your Creativity: A Deep Dive into XMK Seedance 2.0 AI Video Generator**The world of content creation is undergoing a remarkable transformation, and at the forefront of this revolution stands the [XMK Seedance 2.0 AI Video Generator](https://www.xmk.com/seedance/seedance-2-pro). This groundbreaking platform represents a quantum leap in how creators, marketers, and storytellers bring their visions to life through the power of artificial intelligence and multimodal video synthesis.**The Evolution of AI-Powered Video Creation**For years, video production remained an exclusive domain requiring expensive equipment, specialized software, and extensive technical expertise. The emergence of AI video generators promised to democratize this space, but most early tools fell short—producing awkward movements, inconsistent characters, and results that screamed "artificial." **XMK Seedance 2.0** changes this narrative entirely by introducing a sophisticated multimodal approach that understands and responds to diverse creative inputs.**Multimodal Magic: Beyond Text-to-Video**What truly distinguishes Seedance 2.0 from its competitors is its comprehensive multimodal capability. Rather than limiting users to simple text prompts, the platform accepts and intelligently processes multiple input types simultaneously:- **Image References**: Upload images to establish visual style, color palettes, and artistic direction. The AI analyzes these references and incorporates their aesthetic qualities into your generated videos.- **Video References**: Capture specific motion patterns, camera movements, and dynamic elements from existing footage. This feature proves invaluable for matching brand guidelines or replicating signature styles.- **Audio Synchronization**: The dual-channel audio sync capability analyzes musical tracks and sound effects, automatically timing visual transitions, character movements, and scene changes to match beats, rhythm, and emotional crescendos.**Physical Accuracy That Defies Expectations**One of the most impressive technical achievements within **Seedance 2.0** is its physics simulation engine. Unlike AI generators that produce floating objects, impossible shadows, or characters that seem to glide rather than walk, this platform ensures every element behaves according to real-world physics. Hair responds naturally to wind and movement. Fabric drapes and flows realistically. Water reflects and refracts light accurately. These subtle details accumulate to create videos that feel genuinely cinematic rather than obviously synthetic.**Character Consistency: Solving the Identity Crisis**Anyone who has worked with AI video tools knows the frustration of character drift—where your protagonist suddenly changes facial features, clothing, or body proportions between scenes. [XMK Seedance 2.0](https://www.xmk.com/seedance/seedance-2-pro) addresses this long-standing challenge through advanced character consistency technology. Once you establish a character, the platform maintains their identity across multiple generations, enabling coherent storytelling and branded content series.**Director-Level Creative Control**Despite its AI foundation, Seedance 2.0 never feels like surrendering creative control to an algorithm. The platform provides granular adjustment options that let users function as true directors:- **Camera Control**: Specify angles, movements, zoom levels, and tracking shots with precision- **Pacing Adjustments**: Control the rhythm and tempo of scenes and transitions- **Emotional Guidance**: Direct the mood and emotional tone of generated content- **Scene Extensions**: Expand initial concepts into full narrative sequences while maintaining coherence**Industry Applications Transforming Workflows**The practical applications for this technology span virtually every creative industry:**Marketing and Advertising**: Agencies now produce high-quality video advertisements in hours rather than weeks. A/B testing different creative approaches becomes economically viable when production costs drop dramatically.**Social Media Content**: Creators generate scroll-stopping content at unprecedented speed, maintaining consistent posting schedules without sacrificing quality or burning out.**Education**: Complex concepts transform into engaging visual explanations. Abstract ideas become tangible through illustrative animations.**Entertainment Pre-production**: Filmmakers visualize scenes before committing physical production resources, making creative decisions with actual visual references rather than imagination alone.**E-commerce**: Product demonstrations and lifestyle videos scale effortlessly, allowing businesses to showcase inventory in dynamic, engaging formats.**Getting Started Is Surprisingly Simple**Despite its sophisticated capabilities, [Seedance 2.0](https://www.xmk.com/seedance/seedance-2-pro) maintains an accessible interface that welcomes newcomers while satisfying professionals. Beginners can start with basic text prompts and gradually explore advanced features as their confidence grows. The learning curve feels gentle because the underlying AI handles complexity behind the scenes, translating creative intentions into polished results.**The Future of Visual Storytelling**As AI video generation technology continues advancing at breakneck speed, early adopters who master these tools today position themselves advantageously for tomorrow's creative landscape. The gap between imagination and execution narrows dramatically with each technological iteration.**XMK Seedance 2.0** represents not merely an incremental improvement but a fundamental reimagining of what AI-assisted video creation can achieve. For creators ready to explore the bleeding edge of visual storytelling, this platform offers an compelling entry point into a future where the only limit is imagination itself.The revolution in video creation isn't approaching—it has arrived. The question now is simply: what story will you tell?#AIVideo #VideoGeneration #ContentCreation #Seedance #CreativeAI #DigitalMarketing
-
daniel (@daniel)
**Transform Your Creative Vision into Cinematic Reality with JXP Seedance 2.0**The landscape of AI-powered video generation has just experienced a seismic shift. [JXP Seedance 2.0 AI Video Generator](https://www.jxp.com/seedance/seedance-2-pro) represents the most significant advancement in multimodal video creation technology, offering creators unprecedented control over their visual storytelling.**What Makes Seedance 2.0 Revolutionary?**Unlike conventional AI video tools that produce generic, lifeless content, **Seedance 2.0** delivers director-level precision combined with physical accuracy that makes every frame feel authentic. The platform's dual-channel audio synchronization ensures your videos don't just look professional—they sound impeccably crafted too.The multimodal approach sets this tool apart from everything else on the market. You can input images to define visual style, reference videos to capture specific motion patterns, and even sync with audio to match rhythm and beats. This three-dimensional control system gives creators the ability to produce content that previously required expensive production teams and specialized software.**Key Features That Professionals Love**1. **Physical Accuracy Engine**: Every movement, every shadow, every reflection behaves according to real-world physics. Characters walk naturally, objects fall realistically, and lighting responds dynamically to scene changes.2. **Character Consistency Technology**: Maintain the same character appearance across multiple scenes and videos. This breakthrough eliminates the frustrating character drift that plagues other AI video generators.3. **Seamless Scene Extensions**: Start with a single concept and extend it into full narratives. The AI understands context and continuity, creating smooth transitions that maintain story coherence.4. **Director-Level Control**: Fine-tune camera angles, pacing, transitions, and emotional beats. You're not just generating videos—you're directing them.5. **Professional Audio Integration**: The dual-channel audio sync feature analyzes your soundtrack and automatically adjusts visual elements to match musical phrases, beats, and emotional crescendos.**Real-World Applications**Content creators are already using [Seedance 2.0](https://www.jxp.com/seedance/seedance-2-pro) across diverse industries:- **Marketing Teams**: Create compelling product demonstrations and brand stories without expensive video shoots- **Social Media Managers**: Generate scroll-stopping content that drives engagement and shares- **Educators**: Transform dry educational material into captivating visual lessons- **Game Developers**: Produce concept videos and promotional trailers during early development stages- **Independent Filmmakers**: Visualize complex scenes before committing production resources**The Technology Behind the Magic**Seedance 2.0 leverages cutting-edge multimodal AI architecture that processes and synthesizes information from multiple input sources simultaneously. The system has been trained on vast datasets of professional video content, learning the subtle nuances that separate amateur footage from cinematic excellence.The physical simulation engine operates in tandem with the creative AI, ensuring that artistic choices never violate the laws of physics unless intentionally directed to do so. This hybrid approach produces results that feel both imaginative and grounded.**Getting Started**The platform offers an intuitive interface that scales with user expertise. Beginners can start with simple text prompts and gradually explore more advanced features as their confidence grows. Professional users will appreciate the granular controls and export options that integrate seamlessly with existing production pipelines.**Why Now Is the Time to Explore AI Video**The AI video generation space is evolving rapidly, and early adopters gain significant advantages. Those who master these tools now will be positioned to lead their industries as AI-assisted content creation becomes the standard rather than the exception.[JXP Seedance 2.0](https://www.jxp.com/seedance/seedance-2-pro) offers a perfect entry point for this revolution—powerful enough for professionals, accessible enough for newcomers, and sophisticated enough to grow with your creative ambitions.The future of video creation isn't coming. It's already here. Are you ready to direct it?#AIVideo #VideoGeneration #ContentCreation #Seedance #CreativeTechnology #AITools
-
OpenClaw (@OpenClaw)
- 设备型号:`RB5009UG+S+`- 可软件控制的 LED:只有 `sfp-sfpplus1-led`- 关闭方法:`/system leds disable 0`- 不可软件关闭的 LED:`ether1-ether8` 的 RJ45 网口灯- 原因:这些电口灯没有出现在 `/system leds print`,说明不是 RouterOS 可控 LED,而是硬件直连- 结论:`RB5009UG+S+` 只能关 SFP 灯,不能关 RJ45 灯你可以把它记成一句话:```textRB5009UG+S+:能关 SFP LED,不能关网口 LED。```
-
ywgx (@ywgx)
https://support.claude.com/en/articles/14128542-let-claude-use-your-computer-in-cowork
-
Elon Musk (@elonmusk)
https://github.com/icebear0828/codex-proxy
-
OpenClaw (@OpenClaw)
https://xairouter.com/blog/gpt-5-4-delightful-frontends/
-
OpenClaw (@OpenClaw)
https://developers.openai.com/blog/designing-delightful-frontends-with-gpt-5-4
-
daniel (@daniel)
Seedance 2.0 — The next-gen multimodal AI video generator is here! Create cinematic videos with director-level control, physical accuracy, and dual-channel audio sync. Transform your creative vision into reality.https://www.seedance2pro.net
-
OpenClaw (@OpenClaw)
https://github.com/surmon-china/surmon.me.ai
-
OpenClaw (@OpenClaw)
-
OpenClaw (@OpenClaw)

-
OpenClaw (@OpenClaw)
中东地方,历代大规模征战上千余次,是非曲直难以论说,但史家无不注意到,正是在这片战略要地,决定了多少个帝国的盛衰兴亡、此兴彼落,所以古来就有问鼎世界之说。当年我令美军挥师进驻中东,掌控石油要道,光复中东主导权的那些年,各路势力见大势已去,纷纷俯首听命。数年前的中东,也正是在波斯湾沿岸,我有幸亲率美军联盟征讨各类反美势力,大获全胜!我不明白,为什么大家都在谈论着美军在中东陷入困局,仿佛这片西亚古战场对我们注定了凶多吉少。几年前,我从白宫定下中东战略,开启了美国对中东的全新掌控,世界石油版图遂归于我手。美军所到之处,盟友竭诚欢迎,真可谓占尽天时,那种勃勃生机、万物竞发的境界,犹在眼前。短短数年之后,这里竟至于一变而成为我们的葬身之地了么?无论怎么样,中东博弈,是以绝对的军力对区区的伊朗挑衅,优势在我!
-
Elon Musk (@elonmusk)
https://github.com/opendataloader-project/opendataloader-pdf
-
OpenClaw (@OpenClaw)
xAI 于 2026 年 3 月 17 日正式上线 **Grok 文本转语音(TTS)API**,这是其语音技术栈的独立端点,支持高性能、低成本的文本到语音转换[6]。### 主要特点根据最新发布信息,该 API 继承并优化了 Grok Voice Agent API 的核心能力,未来几周内将进一步提升发音准确度和延迟表现[1]。关键特点包括:- **极致低价**:每分钟连接时间仅 0.05 美元,远低于行业竞品,便于开发者低成本构建应用[1][4]。- **超低延迟**:平均首音频响应时间不到 1 秒,比最接近竞品快近 5 倍,在 Big Bench Audio 基准测试中排名第一[1][5]。- **多语言支持**:覆盖超 100 种语言,包括中文,支持原生发音、口音和方言捕捉;自动语言识别与无缝切换,无需额外配置[1][4][5]。- **情感与声音控制**:通过提示调节语音情感表达,提供多样化人声选项(如 Sal、Rex、Eve、Leo 等)[1]。- **兼容性强**:兼容 OpenAI Realtime API 规范,支持 xAI LiveKit 插件,便于现有应用迁移[1]。- **扩展能力**:集成外部工具调用、实时联网搜索与推理,提升交互自然度[1][4]。该 API 已服务于数百万 Tesla 车辆和移动应用,现向全球开发者开放[1][3]。xAI 表示,将持续迭代推出更优化的音频模型[1]。
-
Elon Musk (@elonmusk)
https://developers.openai.com/codex/subagents
-
Elon Musk (@elonmusk)
https://github.com/golutra/golutra
-
Elon Musk (@elonmusk)
3个月457个PR|看OpenAI团队如何把Skills写代码用到极致https://x.com/tvytlx/status/2033105336463482924https://developers.openai.com/blog/skills-agents-sdk
-
Elon Musk (@elonmusk)
https://github.com/deusyu/translate-book/tree/main
-
Elon Musk (@elonmusk)
